|
|
481.
|
|
|
@FUNCTION=RANDBETWEEN 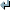
@SYNTAX=RANDBETWEEN(bottom,top)
@DESCRIPTION=RANDBETWEEN function returns a random integer number between and including @bottom and @top.
* If @bottom is non-integer, it is rounded up.
* If @top is non-integer, it is rounded down.
* If @bottom > @top, RANDBETWEEN returns #NUM! error.
* This function is Excel compatible.
@EXAMPLES=
RANDBETWEEN(3,7).
@SEEALSO=RAND,RANDUNIFORM |
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
|
512.
|
|
|
@FUNCTION=TRIMMEAN
@SYNTAX=TRIMMEAN(ref,fraction)
@DESCRIPTION=TRIMMEAN returns the mean of the interior of a data set. @ref is the list of numbers whose mean you want to calculate and @fraction is the fraction of the data set excluded from the mean. For example, if @fraction=0.2 and the data set contains 40 numbers, 8 numbers are trimmed from the data set (40 x 0.2): the 4 largest and the 4 smallest. To avoid a bias, the number of points to be excluded is always rounded down to the nearest even number.
* This function is Excel compatible.
@EXAMPLES=
Let us assume that the cells A1, A2, ..., A5 contain numbers 11.4, 17.3, 21.3, 25.9, and 40.1. Then
TRIMMEAN(A1:A5,0.2) equals 23.2.
@SEEALSO=AVERAGE,GEOMEAN,HARMEAN,MEDIAN,MODE |
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
|
541.
|
|
|
@FUNCTION=TDIST
@SYNTAX=TDIST(x,dof,tails)
@DESCRIPTION=TDIST function returns the Student's t-distribution. @dof is the degree of freedom and @tails is 1 or 2 depending on whether you want one-tailed or two-tailed distribution.
@tails = 1 returns the size of the right tail.
* If @dof < 1 TDIST returns #NUM! error.
* If @tails is neither 1 or 2 TDIST returns #NUM! error.
* This function is Excel compatible for non-negative @x.
Warning: the parameterization of this function is different from what is used for, e.g., NORMSDIST. This is a common source of mistakes, but necessary for compatibility.
@EXAMPLES=
TDIST(2,5,1) equals 0.050969739.
TDIST(-2,5,1) equals 0.949030261.
TDIST(0,5,2) equals 1.
@SEEALSO=TINV,TTEST |
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
|
542.
|
|
|
@FUNCTION=TINV
@SYNTAX=TINV(p,dof)
@DESCRIPTION=TINV function returns the inverse of the two-tailed Student's t-distribution.
* If @p < 0 or @p > 1 or @dof < 1 TINV returns #NUM! error.
* This function is Excel compatible.
Warning: the parameterization of this function is different from what is used for, e.g., NORMSINV. This is a common source of mistakes, but necessary for compatibility.
@EXAMPLES=
TINV(0.4,32) equals 0.852998454.
@SEEALSO=TDIST,TTEST |
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
|
554.
|
|
|
@FUNCTION=NORMDIST
@SYNTAX=NORMDIST(x,mean,stddev,cumulative)
@DESCRIPTION=The NORMDIST function returns the value of the probability density function or the cumulative distribution function for the normal distribution with the mean given by @mean, and the standard deviation given by @stddev. If @cumulative is FALSE, NORMDIST returns the value of the probability density function at the value @x. If @cumulative is TRUE, NORMDIST returns the value of the cumulative distribution function at @x.
* If @stddev is 0 NORMDIST returns #DIV/0! error.
* This function is Excel compatible.
@EXAMPLES=
NORMDIST(2,1,2,0) equals 0.176032663.
@SEEALSO=POISSON |
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
|
566.
|
|
|
@FUNCTION=LARGE
@SYNTAX=LARGE(n, k)
@DESCRIPTION=LARGE returns the k-th largest value in a data set.
* If data set is empty LARGE returns #NUM! error.
* If @k <= 0 or @k is greater than the number of data items given LARGE returns #NUM! error.
* This function is Excel compatible.
@EXAMPLES=
Let us assume that the cells A1, A2, ..., A5 contain numbers 11.4, 17.3, 21.3, 25.9, and 40.1. Then
LARGE(A1:A5,2) equals 25.9.
LARGE(A1:A5,4) equals 17.3.
@SEEALSO=PERCENTILE,PERCENTRANK,QUARTILE,SMALL |
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
|
567.
|
|
|
@FUNCTION=SMALL
@SYNTAX=SMALL(n, k)
@DESCRIPTION=SMALL returns the k-th smallest value in a data set.
* If data set is empty SMALL returns #NUM! error.
* If @k <= 0 or @k is greater than the number of data items given SMALL returns #NUM! error.
* This function is Excel compatible.
@EXAMPLES=
Let us assume that the cells A1, A2, ..., A5 contain numbers 11.4, 17.3, 21.3, 25.9, and 40.1. Then
SMALL(A1:A5,2) equals 17.3.
SMALL(A1:A5,4) equals 25.9.
@SEEALSO=PERCENTILE,PERCENTRANK,QUARTILE,LARGE |
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
|
584.
|
|
|
@FUNCTION=LINEST
@SYNTAX=LINEST(known_y's[,known_x's[,const[,stat]]])
@DESCRIPTION=LINEST function calculates the ``least squares'' line that best fit to your data in @known_y's. @known_x's contains the corresponding x's where y=mx+b.
LINEST returns an array having two columns and one row. The slope (m) of the regression line y=mx+b is given in the first column and the y-intercept (b) in the second.
If @stat is TRUE, extra statistical information will be returned. Extra statistical information is written below the regression line coefficients in the result array. Extra statistical information consists of four rows of data. In the first row the standard error values for the coefficients m1, (m2, ...), b are represented. The second row contains the square of R and the standard error for the y estimate. The third row contains the F-observed value and the degrees of freedom. The last row contains the regression sum of squares and the residual sum of squares.
* If @known_x's is omitted, an array {1, 2, 3, ...} is used.
* If @known_y's and @known_x's have unequal number of data points, LINEST returns #NUM! error.
* If @const is FALSE, the line will be forced to go through the origin, i.e., b will be zero. The default is TRUE.
* The default of @stat is FALSE.
@EXAMPLES=
@SEEALSO=LOGEST,TREND |
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
|
588.
|
|
|
@FUNCTION=LOGEST
@SYNTAX=LOGEST(known_y's[,known_x's,const,stat])
@DESCRIPTION=LOGEST function applies the ``least squares'' method to fit an exponential curve of the form
[tab]y = b * m{1}^x{1} * m{2}^x{2}... to your data.
If @stat is TRUE, extra statistical information will be returned. Extra statistical information is written below the regression line coefficients in the result array. Extra statistical information consists of four rows of data. In the first row the standard error values for the coefficients m1, (m2, ...), b are represented. The second row contains the square of R and the standard error for the y estimate. The third row contains the F-observed value and the degrees of freedom. The last row contains the regression sum of squares and the residual sum of squares.
* If @known_x's is omitted, an array {1, 2, 3, ...} is used. LOGEST returns an array { m{n},m{n-1}, ...,m{1},b }.
* If @known_y's and @known_x's have unequal number of data points, LOGEST returns #NUM! error.
* If @const is FALSE, the line will be forced to go through (0,1),i.e., b will be one. The default is TRUE.
* The default of @stat is FALSE.
@EXAMPLES=
@SEEALSO=GROWTH,TREND |
|
|
[tab] represents a tab character.
Please write it exactly the same way, [tab], in your
translation.
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
|
632.
|
|
|
@FUNCTION=READDBTABLE
@SYNTAX=READDBTABLE(dsn,username,password,table)
@DESCRIPTION=The READDBTABLE function lets you get the contents of a table, as stored in a database. For using it, you need first to set up a libgda data source.
Note that this function returns all the rows in the given table. If you want to get data from more than one table or want a more precise selection (conditions), use the EXECSQL function.
@EXAMPLES=
To get all the data from the table "Customers" present in the "mydatasource" GDA data source, you would use:
READDBTABLE("mydatasource","username","password","customers")
@SEEALSO=EXECSQL |
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
