|
|
1345.
|
|
|
extra operand %s not allowed with -%c
|
|
|
|
|
追加のオペランド %s は -%c と併せて使用できません
|
|
Translated by
Yasuaki Taniguchi
|
|
|
|
Located in
src/sort.c:4797
|
|
|
1346.
|
|
|
the suffix length needs to be at least %<PRIuMAX>
|
|
|
|
|
接尾辞の長さは少なくとも %<PRIuMAX> 必要です
|
|
Translated by
Akihiro Motoki
|
|
|
|
Located in
src/split.c:209
|
|
|
1347.
|
|
|
Usage: %s [OPTION]... [FILE [PREFIX]] 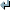
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
使用法: %s [OPTION]... [FILE [PREFIX]]
|
|
Translated by
Akihiro Motoki
|
|
|
|
Located in
src/split.c:225
|
|
|
1348.
|
|
|
Output pieces of FILE to PREFIXaa, PREFIXab, ...;
default size is 1000 lines, and default PREFIX is 'x'.
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
INPUT を PREFIXaa, PREFIXab, ... という固定サイズのファイルに分割します。
デフォルトのサイズは 1000 行です。デフォルトの PREFIX は 'x' です。
|
|
Translated by
Akihiro Motoki
|
|
|
|
Located in
src/split.c:229
|
|
|
1349.
|
|
|
-a, --suffix-length=N generate suffixes of length N (default %d)
--additional-suffix=SUFFIX append an additional SUFFIX to file names
-b, --bytes=SIZE put SIZE bytes per output file
-C, --line-bytes=SIZE put at most SIZE bytes of records per output file
-d use numeric suffixes starting at 0, not alphabetic
--numeric-suffixes[=FROM] same as -d, but allow setting the start value
-x use hex suffixes starting at 0, not alphabetic
--hex-suffixes[=FROM] same as -x, but allow setting the start value
-e, --elide-empty-files do not generate empty output files with '-n'
--filter=COMMAND write to shell COMMAND; file name is $FILE
-l, --lines=NUMBER put NUMBER lines/records per output file
-n, --number=CHUNKS generate CHUNKS output files; see explanation below
-t, --separator=SEP use SEP instead of newline as the record separator;
'\0' (zero) specifies the NUL character
-u, --unbuffered immediately copy input to output with '-n r/...'
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
 represents a space character.
Enter a space in the equivalent position in the translation.
represents a space character.
Enter a space in the equivalent position in the translation.
|
|
|
|
|
-a, --suffix-length=N 接尾辞の長さを N にする (デフォルト: %d)
--additional-suffix=SUFFIX ファイル名に SUFFIX を追加で付加する
-b, --bytes=SIZE 出力ファイル毎の大きさを SIZE バイトにする
-C, --line-bytes=SIZE 出力ファイルに含まれる行の最大サイズを SIZE にする
-d 接尾辞を英字ではなく 0 で始まる数字にする
--numeric-suffixes[=FROM] -d と同様だが、開始番号を設定できる
-x 接頭辞を英字ではなく 0 で始まる 16 進数にする
--hex-suffixes[=FROM] -x と同様だが、開始番号を設定できる
-e, --elide-empty-files '-n' を使用した時に空ファイルを作成しない
--filter=COMMAND シェルコマンド COMMAND にファイル名を $FILE として出力する
-l, --lines=NUMBER 出力ファイル毎の行数/レコード数を NUMBER 行/個にする
-n, --number=CHUNKS 作成する出力ファイル数を CHUNKS 個にする。下記の説明を参照
-t, --separator=SEP レコードの区切りとして改行ではなく SEP を使用する。
'\0' (zero) は NUL 文字を意味する
-u, --unbuffered '-n r/...' を使用した時に、すぐに入力を出力にコピーする
|
|
Translated by
Akihiro Motoki
|
|
|
|
Located in
src/split.c:237
|
|
|
1350.
|
|
|
--verbose print a diagnostic just before each
output file is opened
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
represents a space character.
Enter a space in the equivalent position in the translation.
|
|
|
|
|
--verbose 各出力ファイルを開く前に診断メッセージを表示する
|
|
Translated by
Akihiro Motoki
|
|
|
|
Located in
src/split.c:255
|
|
|
1351.
|
|
|
CHUNKS may be:
N split into N files based on size of input
K/N output Kth of N to stdout
l/N split into N files without splitting lines/records
l/K/N output Kth of N to stdout without splitting lines/records
r/N like 'l' but use round robin distribution
r/K/N likewise but only output Kth of N to stdout
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
represents a space character.
Enter a space in the equivalent position in the translation.
|
|
|
|
|
塊 (CHUNKS) には以下を指定できます:
N 入力サイズに基づいて N 個のファイルに分割する
K/N N 個中 K 番目を標準出力に出力する
l/N N 個のファイルに分割すが、行やレコード内の分割は行わない
l/K/N N 個中 K 番目を標準出力に出力するが、行やレコード内の分割は行わない
r/N 'l' と同様だがラウンドロビン分割をする
r/K/N 上記と同様だが N 個中 K 番目を標準出力に出力する
|
|
Translated by
Akihiro Motoki
|
|
|
|
Located in
src/split.c:262
|
|
|
1352.
|
|
|
output file suffixes exhausted
|
|
|
|
|
出力ファイルの接尾辞を使い果たしました
|
|
Translated by
Yasuaki Taniguchi
|
|
|
|
Located in
src/split.c:465
|
|
|
1353.
|
|
|
creating file %s
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
ファイル %s を作成しています
|
|
Translated by
Yasuaki Taniguchi
|
|
|
|
Located in
src/split.c:477
|
|
|
1354.
|
|
|
%s would overwrite input; aborting
|
|
|
|
|
%s が入力を上書きしてしまいます。中止します
|
|
Translated by
Akihiro Motoki
|
|
|
|
Located in
src/split.c:490
|
