|
|
1561.
|
|
|
tabs are too far apart
|
|
|
|
|
タブが離れすぎています
|
|
Translated by
Yasuaki Taniguchi
|
|
|
|
Located in
src/expand-common.c:86
|
|
|
1562.
|
|
|
tab stop value is too large
|
|
|
|
|
タブ幅が大きすぎます
|
|
Translated by
Yasuaki Taniguchi
|
|
|
|
Located in
src/unexpand.c:303
|
|
|
1563.
|
|
|
Usage: %s [OPTION]... [INPUT [OUTPUT]] 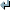
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
使用法: %s [OPTION]... [INPUT [OUTPUT]]
|
|
Translated by
Yasuaki Taniguchi
|
| In upstream: |
|
使用法: %s [オプション]... [入力元 [出力先]]
|
|
|
Suggested by
Masahito Yamaga
|
|
|
|
Located in
src/uniq.c:164
|
|
|
1564.
|
|
|
Filter adjacent matching lines from INPUT (or standard input),
writing to OUTPUT (or standard output).
With no options, matching lines are merged to the first occurrence.
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
INPUT (または標準入力) から行を読み込み、
連続する同じ行を取り除いて、OUTPUT (または標準出力) に出力します。
オプションが指定されない場合、連続する同じ行は最初に見つけた行にまとめられます。
|
|
Translated by
Akihiro Motoki
|
|
|
|
Located in
src/uniq.c:168
|
|
|
1565.
|
|
|
-c, --count prefix lines by the number of occurrences
-d, --repeated only print duplicate lines
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
 represents a space character.
Enter a space in the equivalent position in the translation.
represents a space character.
Enter a space in the equivalent position in the translation.
|
|
|
|
|
-c, --count 行の前に発生回数を出力する
-d, --repeated 重複した行のみ出力する
|
|
Translated by
Yasuaki Taniguchi
|
| In upstream: |
|
-c, --count 入力中に続けて出現した行の回数を表示
-d, --repeated 重複した行のみを出力
|
|
|
Suggested by
Masahito Yamaga
|
|
|
|
Located in
src/uniq.c:147
|
|
|
1566.
|
|
|
-D, --all-repeated[=delimit-method] print all duplicate lines
delimit-method={none(default),prepend,separate}
Delimiting is done with blank lines
-f, --skip-fields=N avoid comparing the first N fields
-i, --ignore-case ignore differences in case when comparing
-s, --skip-chars=N avoid comparing the first N characters
-u, --unique only print unique lines
-z, --zero-terminated end lines with 0 byte, not newline
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
represents a space character.
Enter a space in the equivalent position in the translation.
|
|
|
|
|
-D, --all-repeated[=delimit-method] 全ての重複した行を出力する
delimit-method={none(default),prepend,separate}
空白行で区切る
-f, --skip-fields=N 最初の N 個のフィールドを比較しない
-i, --ignore-case 比較で大文字と小文字の違いを無視する
-s, --skip-chars=N 最初の N 文字は比較しない
-u, --unique 重複していない行のみ出力する
-z, --zero-terminated 行の終わりを (改行ではなく) 0 とする
|
|
Translated by
Yasuaki Taniguchi
|
|
|
|
Located in
src/uniq.c:151
|
|
|
1567.
|
|
|
-w, --check-chars=N compare no more than N characters in lines
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
represents a space character.
Enter a space in the equivalent position in the translation.
|
|
|
|
|
-w, --check-chars=N 行の中で N 文字以上を比較しない
|
|
Translated by
Yasuaki Taniguchi
|
| In upstream: |
|
-w, --check-chars=N 行の比較を最初の N 文字で行う
|
|
|
Suggested by
Akihiro Motoki
|
|
|
|
Located in
src/uniq.c:202
|
|
|
1568.
|
|
|
A field is a run of blanks (usually spaces and/or TABs), then non-blank
characters. Fields are skipped before chars.
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
フィールドとは空白 (通常はスペース、タブ、その両方) が一つ以上連続し、
その後に空白以外の文字が続いているものです。
文字の前のフィールドはスキップされます。
|
|
Translated by
Akihiro Motoki
|
|
|
|
Located in
src/uniq.c:207
|
|
|
1569.
|
|
|
Note: 'uniq' does not detect repeated lines unless they are adjacent.
You may want to sort the input first, or use 'sort -u' without 'uniq'.
Also, comparisons honor the rules specified by 'LC_COLLATE'.
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
Located in
src/uniq.c:219
|
|
|
1570.
|
|
|
too many repeated lines
|
|
|
|
|
重複した行が多すぎます
|
|
Translated by
Yasuaki Taniguchi
|
|
|
|
Located in
src/uniq.c:427
|
