|
|
1272.
|
|
|
extra operand %s not allowed with -%c
|
|
|
|
|
追加のオペランド %s は -%c と併せて使用できません
|
|
Translated by
Yasuaki Taniguchi
|
|
|
|
Located in
src/sort.c:4797
|
|
|
1273.
|
|
|
the suffix length needs to be at least %zu
|
|
|
|
|
接尾辞の長さは最低 %zu 必要です
|
|
Translated by
Yasuaki Taniguchi
|
|
|
|
Located in
src/split.c:187
|
|
|
1274.
|
|
|
Usage: %s [OPTION]... [INPUT [PREFIX]] 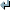
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
使用法: %s [OPTION]... [INPUT [PREFIX]]
|
|
Translated by
Yasuaki Taniguchi
|
|
|
|
Located in
src/split.c:204
|
|
|
1275.
|
|
|
Output fixed-size pieces of INPUT to PREFIXaa, PREFIXab, ...; default
size is 1000 lines, and default PREFIX is 'x'. With no INPUT, or when INPUT
is -, read standard input.
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
Located in
src/split.c:208
|
|
|
1276.
|
|
|
-a, --suffix-length=N generate suffixes of length N (default %d)
--additional-suffix=SUFFIX append an additional SUFFIX to file names.
-b, --bytes=SIZE put SIZE bytes per output file
-C, --line-bytes=SIZE put at most SIZE bytes of lines per output file
-d, --numeric-suffixes[=FROM] use numeric suffixes instead of alphabetic.
FROM changes the start value (default 0).
-e, --elide-empty-files do not generate empty output files with '-n'
--filter=COMMAND write to shell COMMAND; file name is $FILE
-l, --lines=NUMBER put NUMBER lines per output file
-n, --number=CHUNKS generate CHUNKS output files. See below
-u, --unbuffered immediately copy input to output with '-n r/...'
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
 represents a space character.
Enter a space in the equivalent position in the translation.
represents a space character.
Enter a space in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
Located in
src/split.c:216
|
|
|
1277.
|
|
|
--verbose print a diagnostic just before each
output file is opened
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
represents a space character.
Enter a space in the equivalent position in the translation.
|
|
|
|
|
--verbose 各出力ファイルを開く前に診断メッセージを表示する
|
|
Translated by
Akihiro Motoki
|
|
|
|
Located in
src/split.c:255
|
|
|
1278.
|
|
|
CHUNKS may be:
N split into N files based on size of input
K/N output Kth of N to stdout
l/N split into N files without splitting lines
l/K/N output Kth of N to stdout without splitting lines
r/N like 'l' but use round robin distribution
r/K/N likewise but only output Kth of N to stdout
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
Located in
src/split.c:236
|
|
|
1279.
|
|
|
output file suffixes exhausted
|
|
|
|
|
出力ファイルの接尾辞を使い果たしました
|
|
Translated by
Yasuaki Taniguchi
|
|
|
|
Located in
src/split.c:465
|
|
|
1280.
|
|
|
creating file %s
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
|
|
ファイル %s を作成しています
|
|
Translated by
Yasuaki Taniguchi
|
|
|
|
Located in
src/split.c:477
|
|
|
1281.
|
|
|
%s would overwrite input; aborting
|
|
|
|
|
%s が入力を上書きしてしまいます。中止します
|
|
Translated by
Akihiro Motoki
|
|
|
|
Located in
src/split.c:490
|
