|
|
180.
|
|
|
Gettextization: how does it work?
|
|
|
type: =head2
|
|
|
|
|
Gettextization: как это работает?
|
|
Translated by
Skobelev Max
|
|
Reviewed by
Minakov Arthur
|
|
|
|
Located in
doc/po4a.7.pod:837
|
|
|
181.
|
|
|
The idea here is to take the original document and its translation, and to say that the Nth extracted string from the translation is the translation of the Nth extracted string from the original. In order to work, both files must share exactly the same structure. For example, if the files have the following structure, it is very unlikely that the 4th string in translation (of type 'chapter') is the translation of the 4th string in original (of type 'paragraph').
|
|
|
type: textblock
|
|
|
|
|
(no translation yet)
|
|
|
|
Located in
doc/po4a.7.pod:839
|
|
|
182.
|
|
|
Original Translation 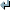
|
|
|
type: verbatim
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
 represents a space character.
Enter a space in the equivalent position in the translation.
represents a space character.
Enter a space in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
Located in
doc/po4a.7.pod:847
|
|
|
183.
|
|
|
chapter chapter
paragraph paragraph
paragraph paragraph
paragraph chapter
chapter paragraph
paragraph paragraph
|
|
|
type: verbatim
|
|
|
represents a line break.
Start a new line in the equivalent position in the translation.
|
|
|
represents a space character.
Enter a space in the equivalent position in the translation.
|
|
|
|
|
(no translation yet)
|
|
|
|
Located in
doc/po4a.7.pod:849
|
|
|
184.
|
|
|
For that, po4a parsers are used on both the original and the translation files to extract po files, and then a third po file is built from them taking strings from the second as translation of strings from the first. In order to check that the strings we put together are actually the translations of each other, document parsers in po4a should put information about the syntactical type of extracted strings in the document (all existing ones do so, yours should also). Then, this information is used to make sure that both documents have the same syntax. In the previous example, it would allow us to detect that string 4 is a paragraph in one case, and a chapter title in another case and to report the problem.
|
|
|
type: textblock
|
|
|
|
|
(no translation yet)
|
|
|
|
Located in
doc/po4a.7.pod:856
|
|
|
185.
|
|
|
In theory, it would be possible to detect the problem, and resynchronize the files afterward (just like diff does). But what we should do of the few strings before desynchronizations is not clear, and it would produce bad results some times. That's why the current implementation don't try to resynchronize anything and verbosely fail when something goes wrong, requiring manual modification of files to fix the problem.
|
|
|
type: textblock
|
|
|
|
|
(no translation yet)
|
|
|
|
Located in
doc/po4a.7.pod:867
|
|
|
186.
|
|
|
Even with these precautions, things can go wrong very easily here. That's why all translations guessed this way are marked fuzzy to make sure that the translator review and check them.
|
|
|
type: textblock
|
|
|
|
|
(no translation yet)
|
|
|
|
Located in
doc/po4a.7.pod:874
|
|
|
187.
|
|
|
Addendum: How does it work?
|
|
|
type: =head2
|
|
|
|
|
(no translation yet)
|
|
|
|
Located in
doc/po4a.7.pod:878
|
|
|
188.
|
|
|
Well, that's pretty easy here. The translated document is not written directly to disk, but kept in memory until all the addenda are applied. The algorithms involved here are rather straightforward. We look for a line matching the position regexp, and insert the addendum before it if we're in mode=before. If not, we search for the next line matching the boundary and insert the addendum after this line if it's an C<endboundary> or before this line if it's a C<beginboundary>.
|
|
|
type: textblock
|
|
|
|
|
(no translation yet)
|
|
|
|
Located in
doc/po4a.7.pod:880
|
|
|
189.
|
|
|
FAQ
|
|
|
type: =head1
|
|
|
|
|
FAQ
|
|
Translated and reviewed by
Minakov Arthur
|
|
|
|
Located in
doc/po4a.7.pod:888
|
